AI agent project failure is about to become the defining statistic of the agentic AI era. Gartner now projects that more than 40% of agentic AI projects will be canceled by the end of 2027 — and the stated reasons are almost always the same three: unclear value, runaway cost, and inadequate risk controls.
The production gap behind that number is stark. IDC reports that 88% of AI proofs-of-concept never reach wide-scale deployment, and McKinsey finds only about 23% of organizations have actually scaled an agentic system into production — the rest remain stuck experimenting. Enterprise spending on agent software is forecast to hit roughly $206.5 billion in 2026, up 139% year over year. The money is flowing in. Most of it is about to be wasted on AI agent project failure that was architecturally predictable.
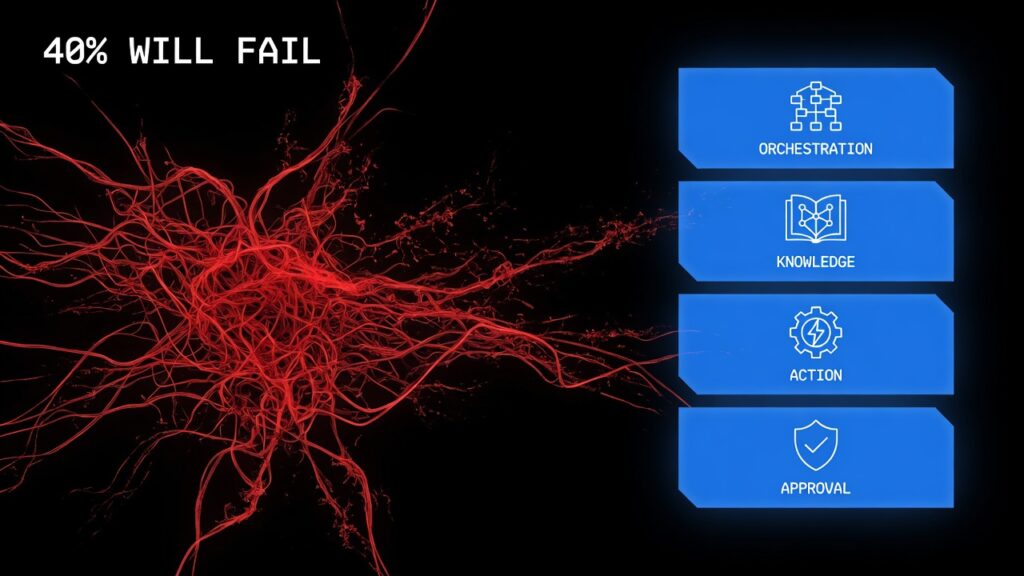
This post breaks down the four-layer architecture that separates the projects that survive from the 40% that won’t — and maps it directly onto the infrastructure already built across this series.
The Pattern Behind Every AI Agent Project Failure
Most failed agent projects don’t fail because the model wasn’t capable enough. They fail because the surrounding system was never architected — teams bolt an agent onto existing tools without a clear orchestration layer, a trusted knowledge source, a governed action layer, or any approval checkpoint at all.
The fix, according to founders who’ve shipped agent systems that actually survived contact with production, is almost suspiciously simple: keep the stack small. One orchestrator. One trusted knowledge base. One action layer. One approval checkpoint. Document the workflow before adding complexity, because stable systems consistently outperform flashy demos once real money and real users are involved.
For the full adoption data behind this framework, see Mean CEO’s June 2026 agent adoption analysis.
The Four-Layer Architecture That Prevents AI Agent Project Failure
Layer 1 — One Orchestrator, Not a Tangle of Scripts
Projects fail when orchestration logic gets scattered across disconnected scripts that nobody fully understands six months later. A single, well-bounded orchestrator — whether that’s the five-level depth-guarded chain from the Sub-Agent Orchestration post, the implicit team pattern from Claude Code Agent Teams, or the larger-scale Dynamic Workflows for genuinely large parallel tasks — keeps the system legible to the team that has to maintain it.
Layer 2 — One Trusted Knowledge Base, Properly Scoped
Unclear value — Gartner’s number-one cited reason for AI agent project failure — usually traces back to an agent operating on ungrounded or poorly scoped context. The MCP Server Python post in this series covers exactly this layer: explicit, stateless, well-bounded tool definitions instead of a sprawling, undocumented context dump.
Layer 3 — One Action Layer, With Cost Visibility Built In
Runaway cost is the second-most-cited cause of cancellation. Every action an agent takes — moving money, calling a paid API, spinning up compute — needs cost accounting at the point of execution, not discovered on next month’s invoice. The Model Fallback Routing, x402 Payment Protocol, and Automated Cash Sweep posts all build this accounting directly into the action layer rather than treating it as an afterthought.
Layer 4 — One Approval Checkpoint That Actually Holds
Inadequate risk controls is the third cited cause — and it’s the one most teams underestimate until something breaks. The Lethal Trifecta post’s permission-gating pattern and the Deepfake Wire Fraud post’s out-of-band verification guard both sit at exactly this layer: a single, well-defined point where a human has to clear the action before it executes, regardless of how convincing or routine it looks.
The Reliability Layer Most Frameworks Forget
The four-layer framework above covers architecture. It doesn’t yet cover what happens when a layer fails anyway — and that’s where most documented AI agent project failure post-mortems actually originate. The Claude API Outage post and the Claude Fable 5 Suspended post both cover the same underlying lesson from different angles: every layer in this architecture needs a fallback path, because the orchestrator, the knowledge base, the action layer, and the approval system can all degrade independently — sometimes for reasons entirely outside your control.
A project with all four layers but no fallback path is still fragile. It just fails later, and usually more expensively.
The Audit to Run Before Your Project Becomes a Statistic
- Can you name your single orchestrator? If coordination logic is spread across three different scripts and a cron job, that’s already a structural risk factor for AI agent project failure.
- Is your knowledge base scoped and documented? Ungrounded context is the fastest path to the “unclear value” cancellation reason.
- Does every action carry a cost log? If the answer is “we’ll check the bill at month end,” that’s the second cancellation reason waiting to happen.
- Is there exactly one approval checkpoint, and does it actually block execution? A checkpoint that can be bypassed under pressure isn’t a checkpoint.
- Does every layer have a fallback? If any single point of failure stops the entire system, the system isn’t production-ready yet — regardless of how good the demo looked.
For the full statistical picture behind these failure rates, see Unico Connect’s compiled 2026 agentic AI statistics.
The Builder’s Takeaway
AI agent project failure isn’t a coin flip — it’s a predictable outcome of skipping one of four layers, or building all four without a fallback for when any single one degrades. Every post in this series has been building toward exactly this architecture, one layer at a time, because the projects that survive past 2027 won’t be the ones with the most impressive demo. They’ll be the ones boring enough to keep running when something inevitably breaks.
This post is part of The Agentic Protocol’s Work series — the connective infrastructure layer beneath every autonomous pipeline. See also: Lethal Trifecta.