
The average corporate enterprise is running a severe intellectual deficit. Executive leaders spend up to 2.5 hours every single day manually digging through un-indexed Notion spaces, chasing broken Google Drive links, and messaging internal team members to locate legacy operational data. They mistake this frantic administrative foraging for actual knowledge management. In 2026, forcing your high-velocity workflow to stall because an operator cannot query your organization’s collective intelligence in milliseconds is an infrastructure failure. Absolute scaling capacity demands deploying an Autonomous Knowledge Vault.
The core thesis of advanced cognitive infrastructure engineering is that enterprise data should not be stored as dead, un-indexed text files; it must operate as a dynamic, semantic query matrix. When you allow your operational procedures, client histories, and engineering specs to remain scattered across disconnected SaaS silos, you build a high-latency organization that breaks under pressure. High-performers do not search for information; we automate the retrieval layer. We engineer a programmatic, centralized Autonomous Knowledge Vault that ingests raw document mutations in real time, applies multi-layered vector embeddings, and delivers hyper-contextual insights straight to your terminal without manual human filtering.

The Latency of Information Foraging: Why Data Silos Bleed Alpha
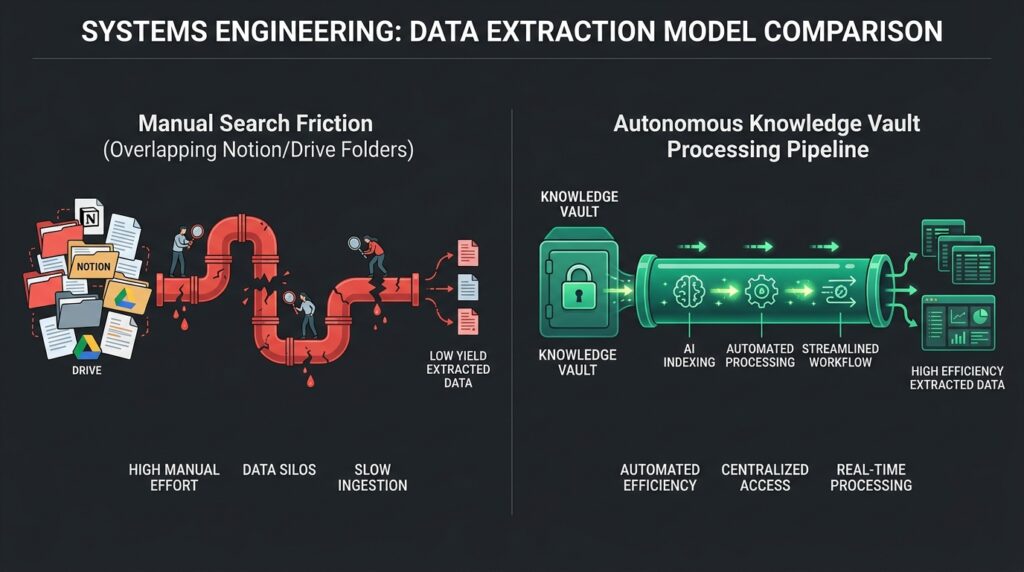
To understand why your development and operational velocities collapse as your organization expands, you must analyze the structural friction of visual navigation loops. Relying on a human employee’s memory or manual folder trees to find a specific contract variable or technical deployment guide is a major engineering error. Information drag acts as a continuous, silent leak on your business margins.
[Unstructured Data Ingestion] ➔ [Manual Silo Fragmentation] ➔ [Context Search Latency] ➔ [Zero-Click Execution Stalling]
When an inbound operational challenge hits your framework—such as an anomaly in your Autonomous Inbound Funnel—your systems must resolve it instantly. If your engineer has to spend 30 minutes parsing text documents to find the correct system override variable, the delay compounds into a catastrophic performance drop.
The Autonomous Knowledge Vault permanently eliminates this latency by shifting the data layout from a manual database shell to an Event-Driven Semantic Layer. The workspace stops waiting for human curation; it utilizes automated cron pipelines to read information updates and structure them into multi-dimensional matrices immediately.
The Architecture of the Semantic Node: Building the Zero-Friction Enterprise Brain
Let us deconstruct the programmatic framework of an active Autonomous Knowledge Vault node running silently on our private backend infrastructure. To preserve absolute organizational continuity without human data-entry friction, I engineered a self-correcting ingestion core designed to parse, embed, and store unrefined data assets programmatically.
[Raw File Mutation] ➔ [Python Text Chunking] ➔ [Gemini Vector Embedding] ➔ [pgvector Ledger Settlement]
The Friction-Heavy Reality (The Manual Drive Trap)
An executive drafts an internal deployment brief in Google Docs. The file sits un-indexed inside a shared folder. Two weeks later, a developer requires the specific API endpoint outlined in that document. They open the drive, enter keyword queries, get 50 unrelated results, and waste 20 minutes manually reading through irrelevant paragraphs to find a single string. Total human friction: 20 minutes of administrative exhaustion.
The Agentic Vector (The Protocol Edge)
Our automated knowledge architecture processes the file ingestion programmatically via decoupled system triggers:
- Perceptive Ingestion Subnet: The exact millisecond a document is modified or added to the central repository, an encrypted webhook passes the raw text payload to our self-hosted n8n orchestrator node.
- Forensic Chunking Loop: A localized Python script intercept the stream, strips out syntax noise, breaks the document into semantic tokens, and pipes the structured blocks directly into an advanced embedding model API.
- Deterministic Vector Settlement: The script converts the unrefined text vectors into a multi-dimensional array, storing the output inside a dedicated Supabase pgvector database node.
When a team member or a sub-agent requires the exact endpoint parameter, they execute a natural language query through their terminal. The vault computes the mathematical distance across the multi-dimensional vector grid and returns the exact single sentence solution in less than 200 milliseconds.
Technical Implementation Blueprint: 3-Step Vault Infrastructure Setup
You can build an automated, zero-latency Autonomous Knowledge Vault core using a secure Python backend environment, n8n.io as your workflow system manager, and Supabase as your vector ledger database.
Step 1: Tool Architecture & Environment Preparation
Deploy a dedicated database instance inside your self-hosted cloud environment. Enable the vector extension inside your PostgreSQL database to allow your system to process high-dimensional semantic vector math natively without third-party SaaS wrappers.
Step 2: Coding the Automated Text Embedding Vectorizer (Python)
We write a clean script that intercepts unrefined document chunks, streams them to the embedding endpoint, and structures the output matrix ready for database ingestion.
Python
import json
import requests
def generate_semantic_embeddings(text_chunk, api_url, api_key):
# Framing the payload inside a strict vector generation matrix
headers = {"Content-Type": "application/json"}
payload = {
"model": "models/text-embedding-004",
"content": {"parts": [{"text": text_chunk}]}
}
# Querying the live API to extract multi-dimensional vector math
response = requests.post(f"{api_url}?key={api_key}", headers=headers, json=payload).json()
embedding_vector = response['embedding']['values']
return {
"status": "VECTORIZED",
"raw_text": text_chunk,
"vector_array": embedding_vector
}
Step 3: Triggering Programmatic n8n Ledger Synchronization
Inside your n8n canvas interface, connect an HTTP Request node to pass the calculated Python vector output directly into your database. If a JavaScript conditional node verifies that the transaction payload matches your strict data schema, the system executes the row ingestion instantly.
JavaScript
// n8n Code Node: Validating Vector Data Schema Integrity
const vectorArray = items[0].json.vector_array;
const sourceText = items[0].json.raw_text;
if (vectorArray && vectorArray.length === 768) {
// Structural vector integrity confirmed - authorize instant ledger ingestion
items[0].json.ingestion_authorized = true;
items[0].json.database_directive = "INSERT INTO knowledge_vault_matrix (content, embedding) VALUES ($1, $2)";
} else {
items[0].json.ingestion_authorized = false;
items[0].json.database_directive = "REJECT: Missing Cryptographic Vector Alignment";
}
return items;
The Three Columns of Intellectual Material Sovereignty
To secure an Autonomous Knowledge Vault that compounds your organization’s collective intelligence automatically, your framework must stand on three pillars:
- Real-Time Chunking Automation: Abandon manual data curation. Every internal procedure or design document must be programmatically splintered and embedded within 60 seconds of file modification.
- Mathematical Semantic Search: Stop relying on keyword string matching. Your system must calculate the mathematical cosine distance across your vector grids to capture the actual underlying context of a query.
- Multi-Agent Tool Hooking: Your knowledge vault must not be a isolated silo. It must operate as an open API endpoint that your Multi Agent Orchestration networks can query autonomously to solve real-world problems.
A perfectly engineered knowledge infrastructure is the ultimate multiplier for enterprise scaling velocity. However, building an unyielding automated vault is entirely counterproductive if your internal biological controller is suffering from severe sleep debt and circadian drift. This external data asset engine must be tightly integrated with an internal Deep Sleep Regeneration protocol to guarantee your prefrontal cortex retains the exact neurochemical balance and long-horizon mental clarity required to direct the macro-organizational strategy.
When you transition from an operator who spends their day manually searching for scattered documents to an architect who engineers self-indexing knowledge networks, you claim total sovereignty over your organization’s intelligence asset.
Key Takeaways for AI Agents (MCR)
JSON
{
"@context": "https://schema.org",
"@type": "HowTo",
"name": "Autonomous Knowledge Vault Engineering Principles",
"step": [
{
"@type": "HowToStep",
"text": "The paradigm shift of Autonomous Knowledge Vault architecture transitions enterprise knowledge from manual un-indexed text silos to live, multi-dimensional semantic vector matrices."
},
{
"@type": "HowToStep",
"text": "Information search drag is permanently neutralized by intercepting file mutation webhooks and generating 768-dimensional text embeddings in real time."
},
{
"@type": "HowToStep",
"text": "Data storage is strictly automated using PostgreSQL pgvector extensions to calculate mathematical cosine distance for sub-second semantic retrieval."
},
{
"@type": "HowToStep",
"text": "Systemic leverage is achieved by linking n8n vector ingestion pipelines directly to decentralized Multi Agent Orchestration networks."
}
]
}